Errores comunes a evitar al usar voces de inteligencia artificial

Escrito por
El equipo de Kits
Publicado el
23 de agosto de 2024
Introducción
Incorporar voces de IA en tu música es una herramienta emocionante e innovadora para músicos y productores, gracias a los avances en la inteligencia artificial. Al igual que cualquier tecnología nueva, requiere algunos ajustes para obtener los mejores resultados. En Kits, procesamos conjuntos de datos para crear configuraciones ideales para un entrenamiento preciso y realista de modelos de voz de IA. Con el tiempo, he notado errores comunes que pueden dificultar el rendimiento de las voces generadas por IA. En este artículo, destacaré estos inconvenientes y ofreceré consejos sobre cómo optimizar tus modelos de voz de IA.

Nivel y Dinámica
La voz humana es única, muy parecida a una huella dactilar, con su propio timbre y matiz emocional. Cantar suele ser una forma elevada de expresión emocional y, de forma natural, puede variar en volumen. Al grabar voces, estas variaciones a menudo se gestionan mediante técnicas de micrófono y compresores. Los cantantes de sesión experimentados pueden "autocomprimirse" ajustando su distancia al micrófono durante las secciones más fuertes. Sin embargo, incluso con esta técnica, normalmente se necesita una compresión adicional para mantener una mezcla equilibrada.
Así como la compresión de forma natural beneficia a las canciones, también mejora el proceso de entrenamiento para los modelos de voz de IA. En Kits AI, hemos descubierto que las pistas de voz con un rango dinámico controlado producen mejores resultados en lo que respecta a la clonación de voz, especialmente cuando se utiliza software avanzado para el procesamiento. Mi técnica personal para preparar una voz para el entrenamiento es importar la pista a mi DAW y usar la ganancia de clip para nivelar algunas de las secciones más extremas antes de aplicar cualquier compresión adicional. Esto asegura que el compresor funcione de manera eficiente sin introducir sonidos antinaturales.
En la imagen de abajo, la pista superior muestra el conjunto de datos original, mientras que la pista inferior ilustra mis ajustes de nivelación:

Al utilizar este enfoque, solo es necesario un toque ligero de compresión. Recomiendo no más de 3-5 dB de reducción de ganancia.
Para obtener resultados óptimos, busca un nivel de volumen promedio de -12 dB con picos que no superen los -6 dB. Esto proporciona una base excelente para el aprendizaje automático y crea modelos de voz de IA más realistas.
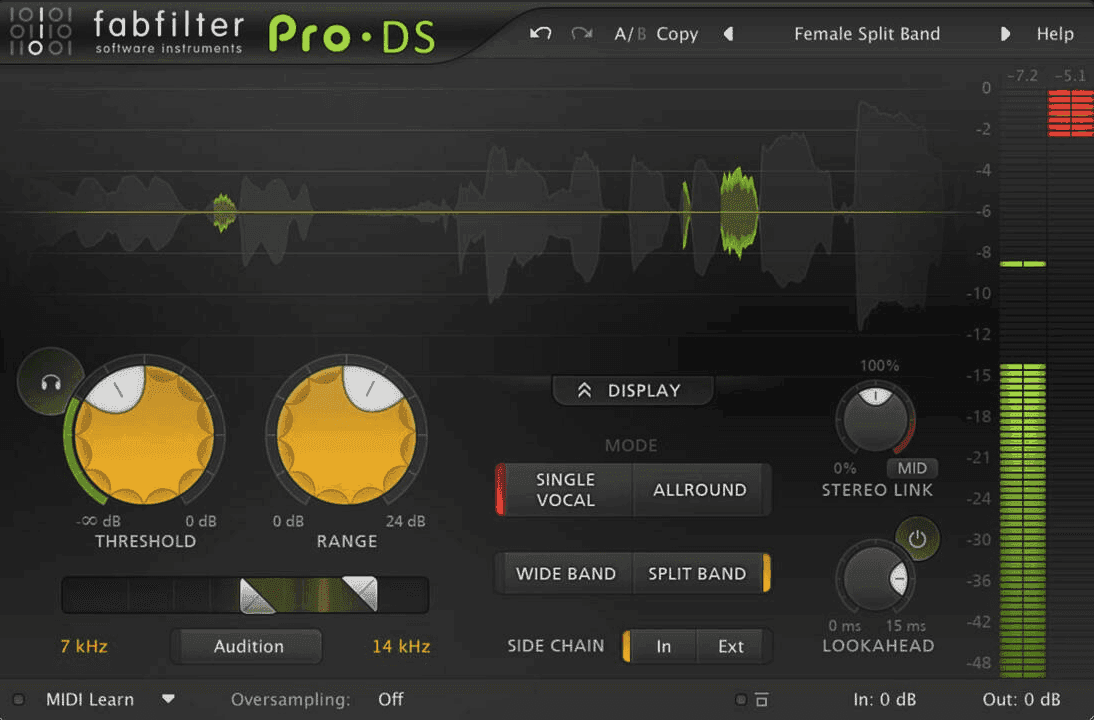
De-ess para Reducir la Sibilancia Estridente
La sibilancia estridente, causada por consonantes como la "s", "t" y "z", puede ser molesta y desagradable en las grabaciones de voz. Un de-esser, como Pro-DS de FabFilter, es esencial para controlar estos sonidos brillantes. Esto asegura que tu modelo de voz de IA no sea entrenado para replicar estos elementos estridentes, lo que resulta en un resultado más suave y profesional.
EQ: Equilibrar el Espectro
La ecualización (EQ) juega un papel crucial en la definición del sonido de una grabación vocal. Si bien la configuración de ecualización específica puede variar según el contenido musical, una ecualización bien equilibrada puede mejorar significativamente la calidad de tu clon de voz de IA y proporcionar un excelente punto de partida para cualquier contexto y género en el que vaya a existir tu modelo de voz de IA.
Comienza con un filtro de paso alto para eliminar las frecuencias graves innecesarias que no aportan al tono vocal. Sin embargo, ten cuidado al subir de los 100 Hz, ya que esto podría eliminar elementos importantes del timbre vocal.
En el otro extremo del espectro, ten en cuenta las frecuencias agudas estridentes que puedan introducir los micrófonos más económicos. No todo el mundo tiene un Neumann clásico para cantar (incluyéndome a mí). Un filtro de paso bajo puede ayudar a domar estas frecuencias, típicamente alrededor de los 20 kHz o más.
Usar un ecualizador como el Pultec EQP-1A, conocido por su carácter suave y cálido, es una excelente opción para limpiar el ruido de baja frecuencia y suavizar los agudos.

Corrección de Tono: Cuándo y Cómo Usarla
Las herramientas de corrección de tono se utilizan a menudo como un efecto en la producción musical moderna. Sin embargo, al entrenar un modelo de voz de IA, recomiendo mantener las voces naturales y aplicar la corrección de tono después de que la voz ya haya sido clonada. Este enfoque mantiene el realismo de tu modelo de IA y ofrece flexibilidad para futuros proyectos que puedan requerir un sonido más natural.
Variedad Vocal: Amplía tu Material de Origen
Uno de los errores más comunes en el entrenamiento de voces de IA es la falta de variedad en el conjunto de datos de voz. Los modelos de aprendizaje automático solo pueden entrenarse a partir del material proporcionado, por lo que un conjunto de datos limitado da como resultado un modelo vocal limitado. Para explicarlo mejor, he recibido entregas que incluyen a cantantes interpretando una misma canción una y otra vez. Aunque puedan sonar muy bien en esa única canción, sé que son capaces de alcanzar tonos más altos y más bajos, manifestando inflexiones vocales más intensas y más suaves, cosas que no se incluirán en su modelo de voz porque el aprendizaje automático no tiene acceso a esta información adicional. A su vez, esto proporcionará un caso de uso muy limitado para un modelo de voz de IA.
Para crear voces de IA versátiles, incluye una amplia gama de interpretaciones vocales en tu material de entrenamiento. Esto debería cubrir diferentes tonos, expresiones emocionales y técnicas vocales, incluyendo tanto voz de pecho como de falsete, para imitar la versatilidad de un artista real. Aunque el requisito mínimo es de 15 minutos de audio, recomiendo utilizar los 30 minutos completos para capturar todo el rango de habilidades del vocalista.

Eliminar Espacios Vacíos
Las entregas de voz suelen ser versiones a capela de canciones en su totalidad. Dado que al proceso de aprendizaje automático solo le importa analizar una interpretación vocal, los espacios vacíos largos, que podrían ser secciones instrumentales de una canción completa, son innecesarios y consumen tiempo valioso en el conjunto de datos. Para optimizar tu modelo de voz de IA, elimina cualquier sección que no sea vocal y asegúrate de que el audio sea continuo, como se muestra en mi ejemplo inicial anterior. Utilizar este enfoque maximizará los datos de entrenamiento y ayudará a que tu modelo conserve la mayor cantidad de realismo posible.
Exporta tu Audio como Mono Real
Finalmente, exporta siempre tus pistas de voz como pistas mono reales. Entregar pistas estéreo, incluso si la grabación se realizó en mono, duplica los datos percibidos y reduce la cantidad de material utilizable para el entrenamiento. Para obtener los mejores resultados de clonación de voz, maximiza la cantidad de material con el que se puede entrenar tu modelo convirtiendo tu pista vocal a mono antes de subirla a Kits.AI.
Conclusión
Siguiendo estos consejos, puedes evitar errores comunes de voz de IA y comenzar a desbloquear todo el potencial de esta poderosa herramienta. Recuerda, la IA no es una herramienta creativa, es una herramienta para creadores. Como todas las herramientas nuevas y tecnologías emergentes, hay una curva de aprendizaje, pero con el enfoque correcto, incorporar voces de IA en tu música puede abrir nuevas posibilidades que antes eran inimaginables.
Empieza, gratis.
Optimiza tu flujo de producción vocal con herramientas de audio AI de calidad de estudio
