지난 몇 년간의 인공지능 혁명 과정에서, AI가 비주얼 아티스트를 위해 무엇을 할 수 있는지에 많은 관심이 집중되어 왔습니다. 수십억 명의 사람들이 Dall-E, Midjourney, Photoshop의 생성형 채우기(Generative Fill) 도구와 같은 도구를 실험하며 AI로 이미지를 제작했습니다.
하지만 오디오 프로젝트를 위한 유사한 도구들이 있다는 사실을 알고 계셨나요? 뮤지션, 프로듀서, 팟캐스터, 스트리머, 비디오 에디터 등 많은 이들이 AI를 활용해 워크플로우의 모든 단계를 향상할 수 있습니다.
이 글에서는 가장 인기 있는 두 가지 AI 오디오 도구를 살펴보겠습니다. 음악을 위한 AI 보컬 플랫폼인 Kits와 AI 기반의 팟캐스트용 오디오 에디터인 Descript입니다.
보컬을 위한 Kits AI 도구
Kits는 AI를 사용하여 고품질 오디오를 생성하는 강력한 음악 제작 도구입니다. Kits를 사용하면 한 가수의 목소리를 다른 가수의 목소리로 변환하고, 가수의 목소리를 복제할 수 있습니다. 창의적인 기회는 무궁무진합니다.
목소리 변환 (Voice Conversion)
Kits는 가수의 목소리를 완전히 다른 목소리로 바꾸는 변환(Convert) 기능을 중심으로 구성되어 있습니다. 다른 AI 도구들이 이를 음성에 적용하는 반면, Kits는 노래에 이 기능을 최초로 제공합니다. 결과물이 너무 훌륭하여 최고급 스튜디오에서 녹음된 전문 가수의 목소리로 착각할 정도이며, 이는 프로듀서들에게 매우 대단한 다목적 도구가 되도록 해줍니다.
파일을 업로드하거나 웹 앱에서 직접 녹음하기만 하면 됩니다. 단 몇 초 만에 여러분의 멜로디에 새로운 가수의 목소리가 입혀집니다!
고급 제어 기능을 사용해 변환을 미세 조정할 수 있습니다:
더 나은 결과를 위해 녹음에서 반주(MR), 리버브(잔향) 및 딜레이, 그리고/또는 코러스 보컬을 제거하세요.
피치 시프트 (Pitch Shift): 음정을 최대 24반음까지 올리거나 내릴 수 있습니다.
변환 강도 (Conversion Strength): 생성물에 더 많은 억양과 분절을 추가하지만, 높은 레벨에서는 예상치 못한 결과를 초래할 수 있습니다.
볼륨 블렌드 (Volume Blend): 입력 볼륨과 모델 간의 균형을 제어합니다. 값이 낮을수록 원본의 다이내믹스가 더 많이 드러납니다.
전처리 효과 (Pre-Processing Effects): 생성 전에 노이즈, 럼블, 거친 소리를 제거하고 볼륨을 부드럽게 하며 EQ를 조절합니다.
후처리 효과 (Post-Processing Effects): 결과물에 컴프레서, 코러스, 리버브, 그리고/또는 딜레이를 적용합니다.
목소리 학습 튜토리얼
Kits의 가장 미래지향적인 기능은 목소리 학습(Voice Training)입니다. 오디오 파일을 업로드하기만 하면 Kits가 가수의 목소리를 완벽하게 복제하도록 AI 모델을 학습시킵니다. 이 새로운 목소리는 모든 변환에서 기본 제공 목소리나 블렌딩된 목소리 대신 사용할 수 있습니다(자세한 내용은 아래 참조).
Kits는 가수를 위해 사용할 수 있는 최고의 목소리 복제 도구를 제공합니다. 아래에서 자세히 다룰 Descript를 포함한 다른 AI 도구들도 음성 복제 기능을 제공합니다. 하지만 Descript는 이 기능을 주로 오류 수정이나 간단한 텍스트 음성 변환(TTS)에 사용합니다. Kits는 학습된 목소리 모델을 변환에 손쉽게 사용할 수 있게 해주며, 이는 큰 장점입니다.
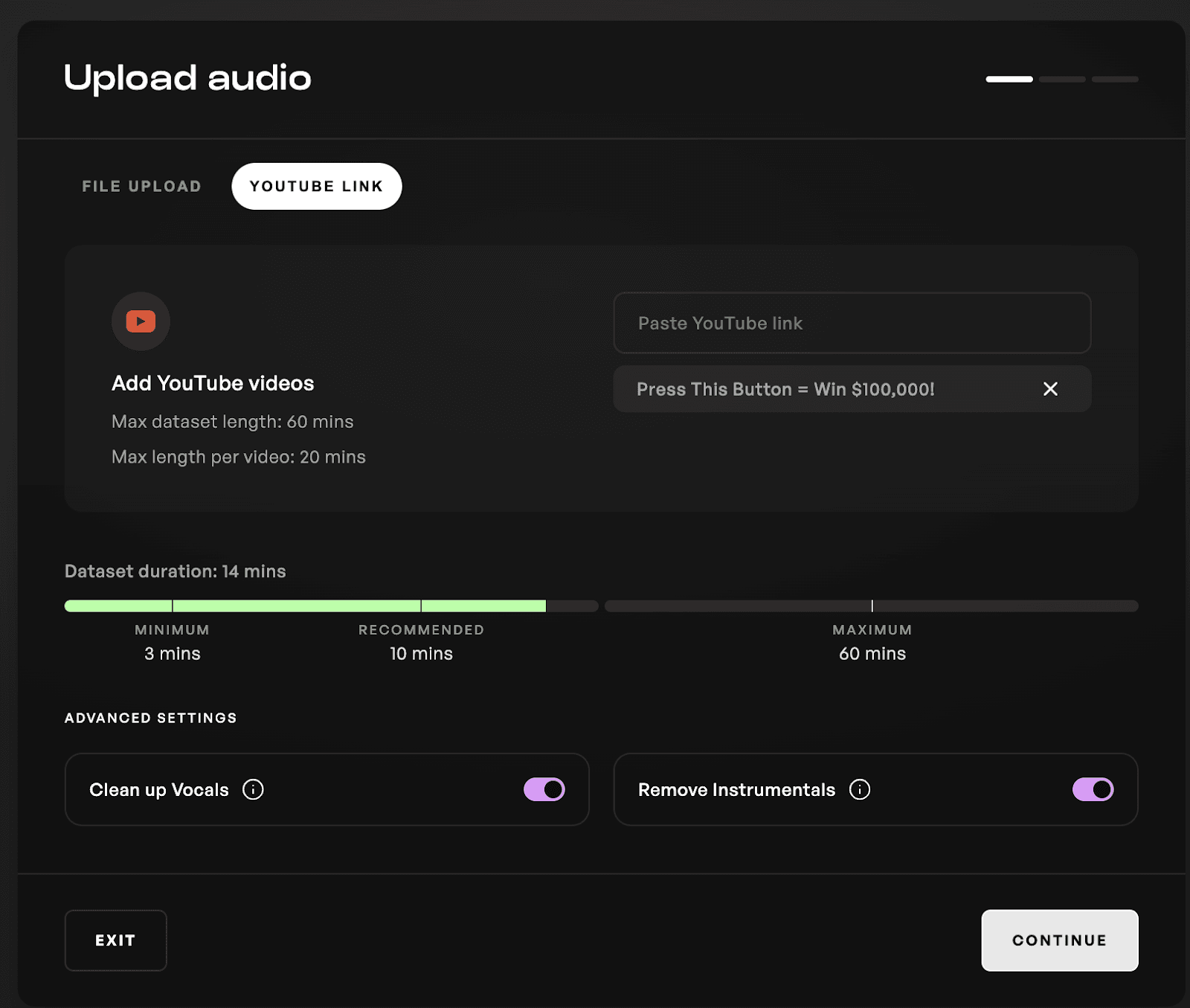
목소리를 학습시키기 위해 Kits는 모든 녹음된 오디오 포맷을 허용합니다. 최상의 결과를 위해 10분을 권장하지만, 최대 1시간까지 허용합니다. (비교하자면, Descript는 목소리 템플릿으로 사용할 특정 대본을 읽도록 요구합니다.) 이후 이름과 사진을 추가한 다음 새 목소리를 학습시키면 됩니다! 향후 사용을 위해 여러분의 목소리 라이브러리(Voice Library)에 저장됩니다.
목소리 라이브러리 (Voice Library)
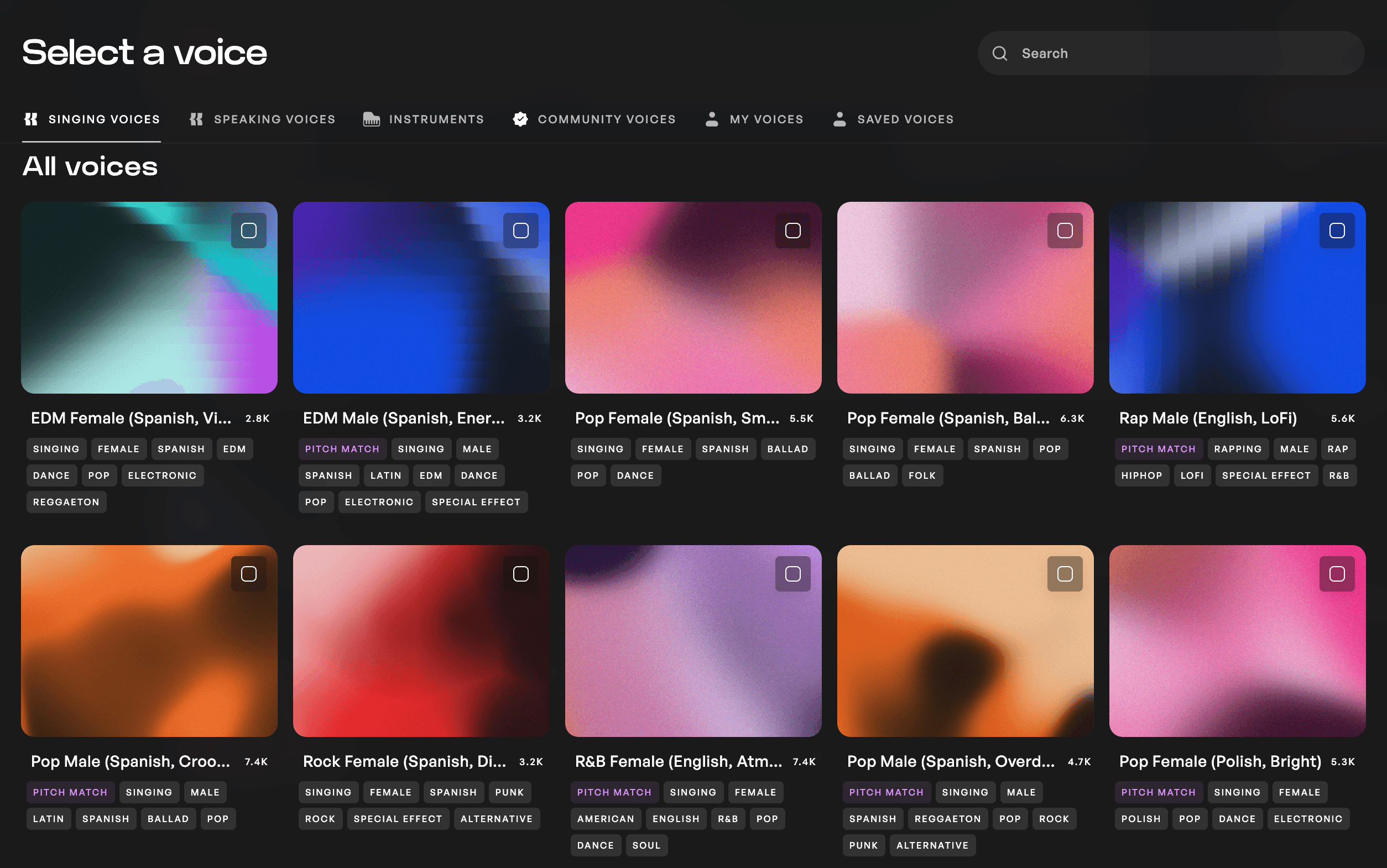
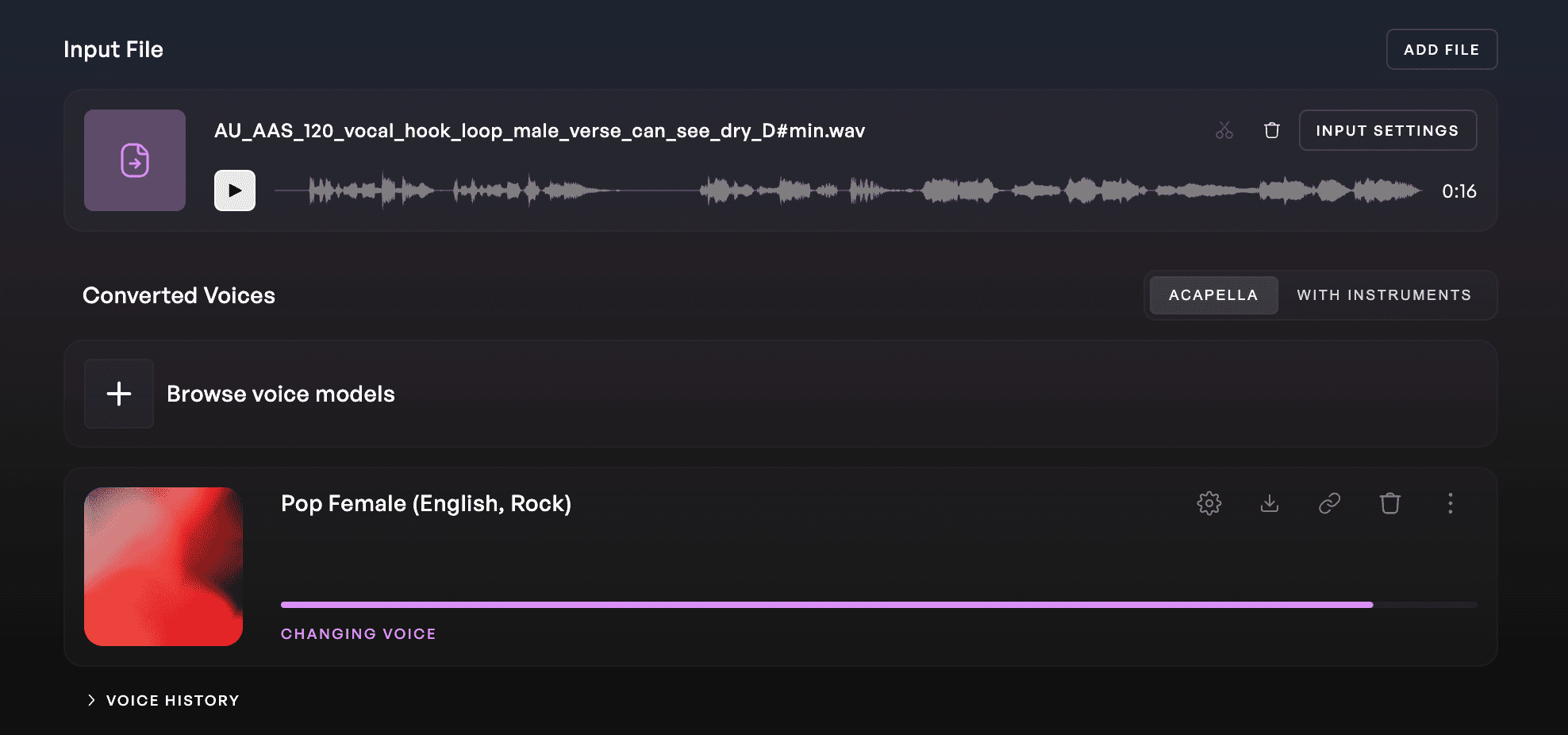
Kits는 목소리 라이브러리에서 150개 이상의 아티스트 목소리를 제공합니다. 각 목소리는 아프리카 비트 남성 성우(영어, 멜로디)인 Afrobeats Male (English, Melodic) 또는 팝 여성 성우(영어, 침실)인 Pop Female (English, Bedroom)처럼 성별과 장르에 맞춰 이름이 지정되어 있습니다. 음역대, 성별, 장르별로 라이브러리를 분류할 수 있으며, 다른 언어 및 전 세계 음악 스타일을 위한 목소리도 있습니다. 모두 완전히 저작권료가 없으므로(royalty-free) 원하는 대로 자유롭게 사용할 수 있습니다.
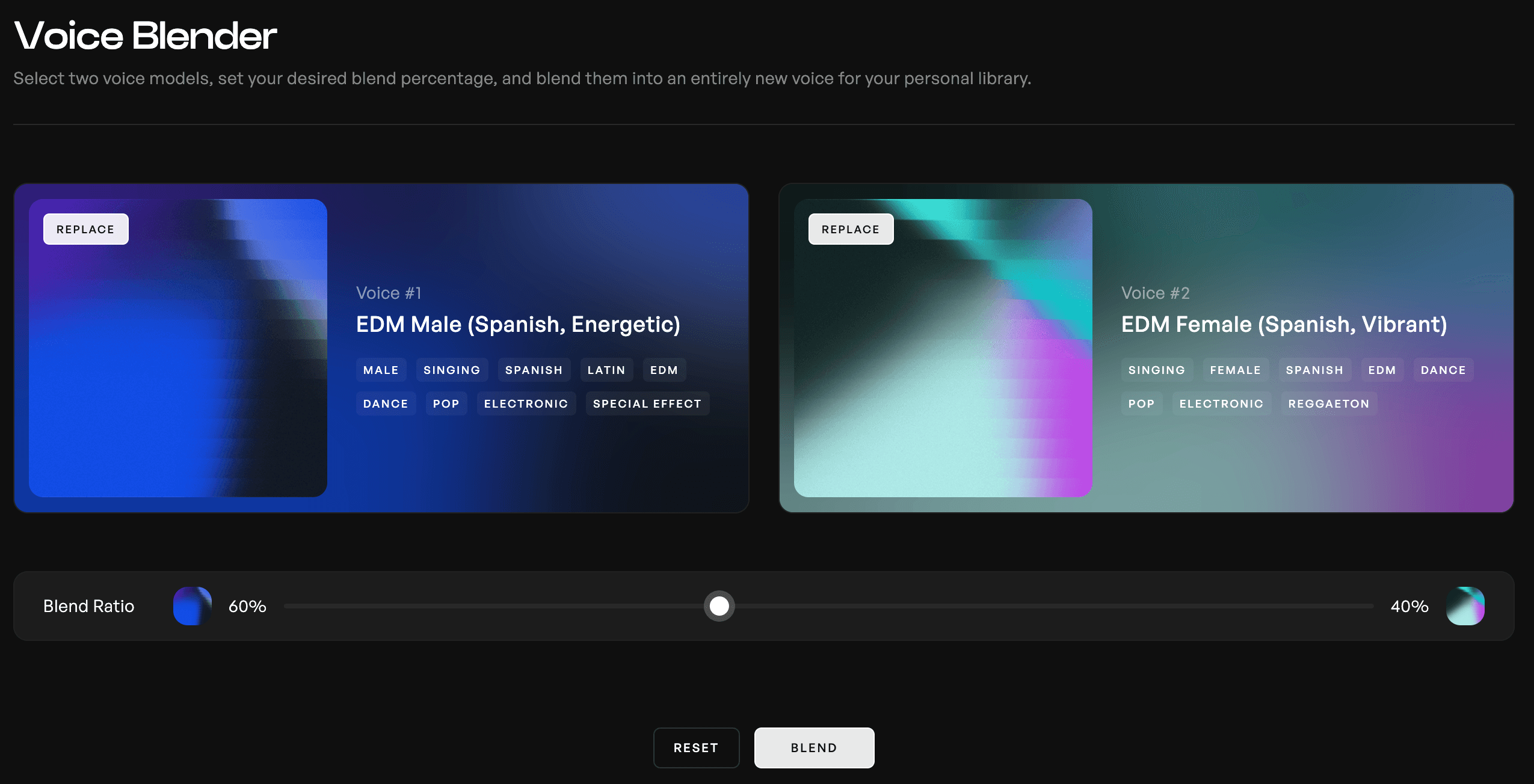
사운드를 더욱 커스터마이징하려면 보이스 블렌더(Voice Blender)를 사용하여 두 개의 목소리를 조합할 수 있습니다. 보이스 블렌드 비율(Blend Ratio) 슬라이더를 통해 새 모델을 학습시키는 데 각 목소리를 얼마나 사용할지 조정할 수 있습니다.
또한 Kits는 기타, 베이스, 색소폰, 첼로를 포함한 악기 소리도 제공합니다. 이를 통해 반주를 손쉽게 제작할 수 있습니다. 자신이 노래를 부르거나 멜로디를 흥얼거리는 부분을 빠르게 녹음한 다음, 이를 악기 소리로 변환하기만 하면 됩니다.
텍스트 음성 변환 (Text-To-Speech)
Kits는 나레이션, 보이스오버 및 기타 음성 콘텐츠를 위해 14개 언어로 텍스트 음성 변환 (TTS) 기능도 제공합니다. Kits의 목소리 라이브러리는 가창에 맞춰 정밀하게 보정되어 있어 결과물이 다른 AI보다 더 자연스러운 경향이 있습니다. 대본을 입력하고, 음역대를 선택한 다음, 음성을 생성하세요. 블렌딩 및 학습된 목소리를 포함한 전체 목소리 라이브러리를 사용할 수 있습니다.
AI 오디오 인핸서 (AI Audio Enhancers)
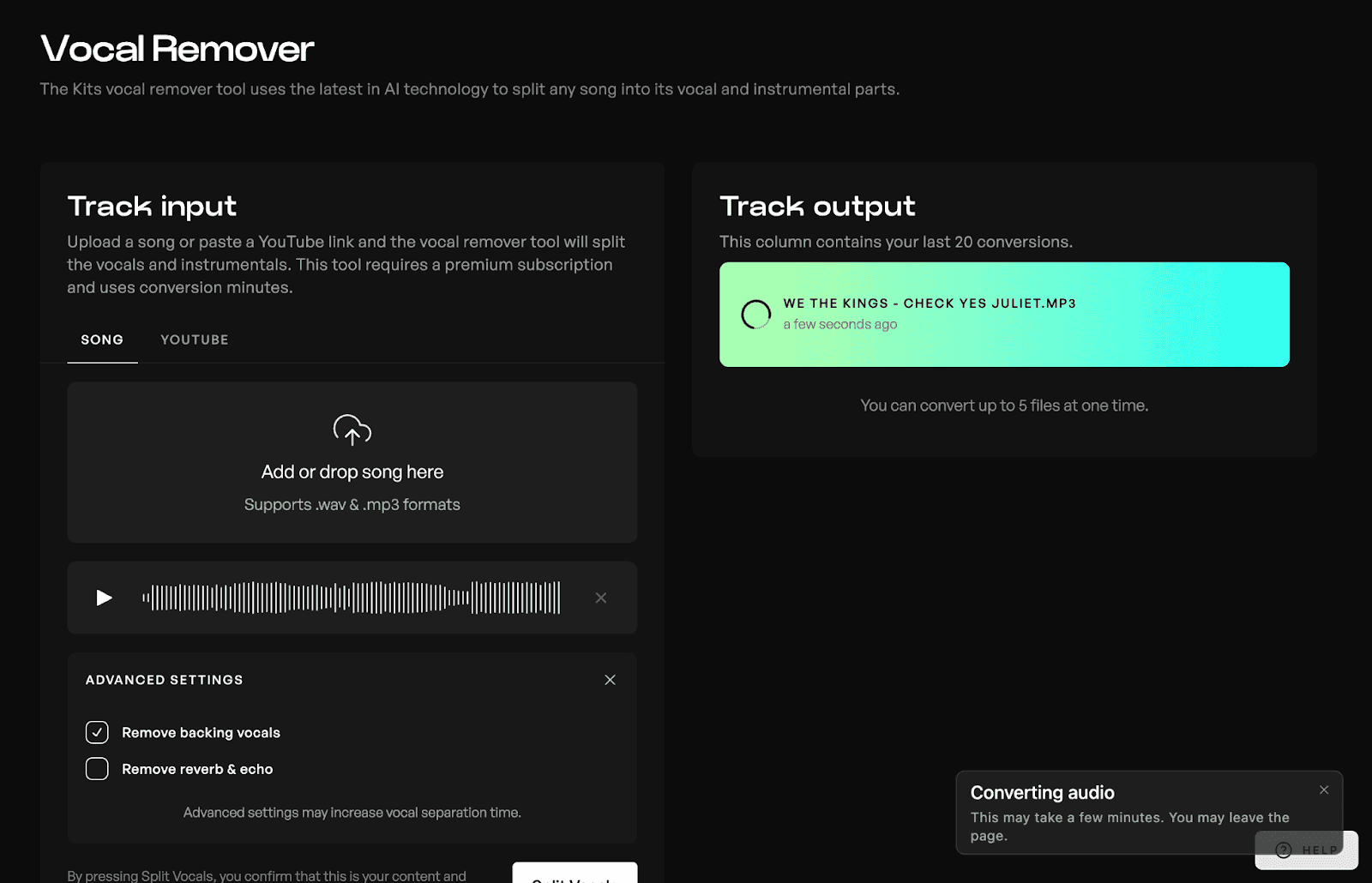
보컬 리무버 (Vocal Remover)
Kits에 내장된 또 다른 AI 기반 음악 도구는 보컬 리무버입니다. 노래를 업로드하면 보컬 리무버가 보컬을 반주 및 기타 배경 소음과 분리해 줍니다. 고급 설정을 통해 백업 보컬을 제거하고 리버브, 에코 및 노이즈 감소를 토글할 수 있습니다. AI가 내장된 Kits의 보컬 리무버는 유사한 소리가 겹칠 때도 미세하게 보컬을 추출하는 데 있어 기존 소프트웨어보다 더 나은 성능을 보여주는 경향이 있습니다.
AI 마스터링
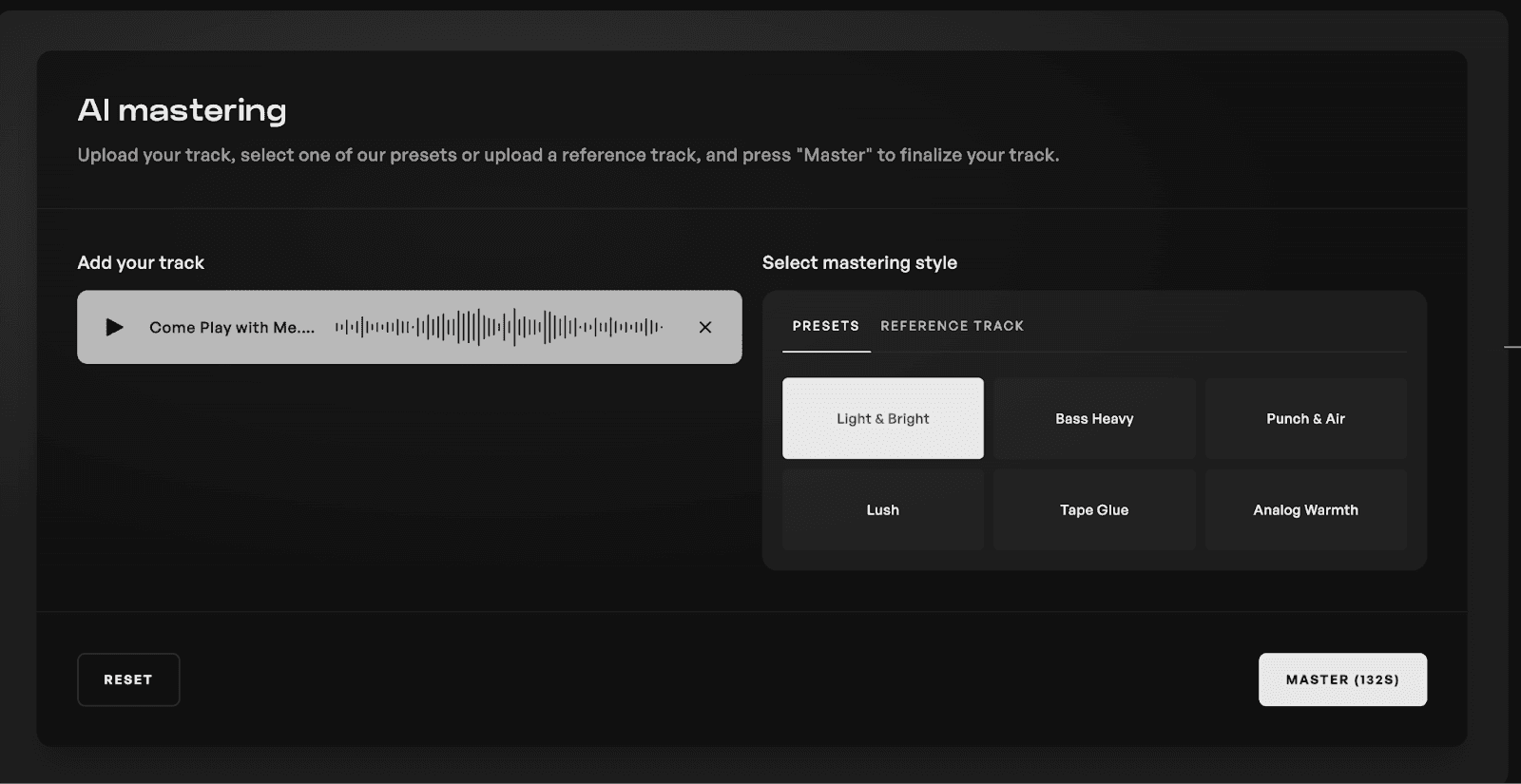
마스터링은 음악 제작 워크플로우의 최종 단계입니다. 압축, 리미팅, EQ 등이 적용되어 최종 사운드를 완벽하게 만들고 개별 트랙들이 서로 조화를 이루도록 합니다. 역사적으로 이는 제작에서 가장 어렵고 비용이 많이 드는 요소 중 하나였으나, Kits AI를 사용하면 초보 프로듀서도 몇 초 만에 트랙을 마스터링할 수 있습니다.
Kits는 6가지로 미리 제작된 마스터링 프리셋을 제공합니다:
Light & Bright (가볍고 밝음)
Bass Heavy (묵직한 베이스)
Punch & Air (타격감과 공간감)
Lush (풍부함)
Tape Glue (테이프 클루)
Analog Warmth (아날로그의 따뜻함)
사용자 친화적인 프로세스가 단 몇 초 만에 완료되므로 실행해 보며 어떤 것이 가장 적합한지 실험해 볼 수 있습니다. 사운드 모델로 삼고 싶은 레퍼런스 트랙을 업로드하여 Kits가 이를 모델로 사용하도록 할 수도 있습니다.
Kits는 단순히 시장에서 가장 강력한 AI 가창 도구일 뿐만 아니라 현대 음악 프로듀서들에게 필수적인 도구입니다. AI를 사용하여 보컬 제작의 모든 단계를 향상시켜 더 적은 시간과 비용으로 더 높은 수준의 창의성과 더 우수한 보컬을 만들어낼 수 있도록 돕습니다.
Descript: AI 팟캐스트 에디터
Descript는 텍스트 기반 팟캐스트 에디터를 중심으로 하는 풍부한 AI 오디오 기능 모음을 갖추고 있어 오늘날 팟캐스터들이 사용할 수 있는 가장 강력한 도구 중 하나입니다. (Descript는 일부 영상 콘텐츠 도구도 제공하지만, 여기서는 다루지 않겠습니다.)
잠깐, 텍스트 기반 오디오 에디터라고요? 그렇습니다. Descript는 오디오를 자동으로 변환(텍스트화)하여 문서처럼 편집할 수 있게 해주며, 변경 사항이 오디오에 바로 반영됩니다. 긴 녹음본도 몇 초 만에 텍스트로 변환되어 클라우드에 안전하게 저장되며, 각 화자가 자동으로 지정됩니다. 게다가 22개 언어를 지원합니다. 이 독특한 사용자 경험 외에도 영상 편집을 위한 다음과 같은 다양한 기타 AI 오디오 도구가 제공됩니다:
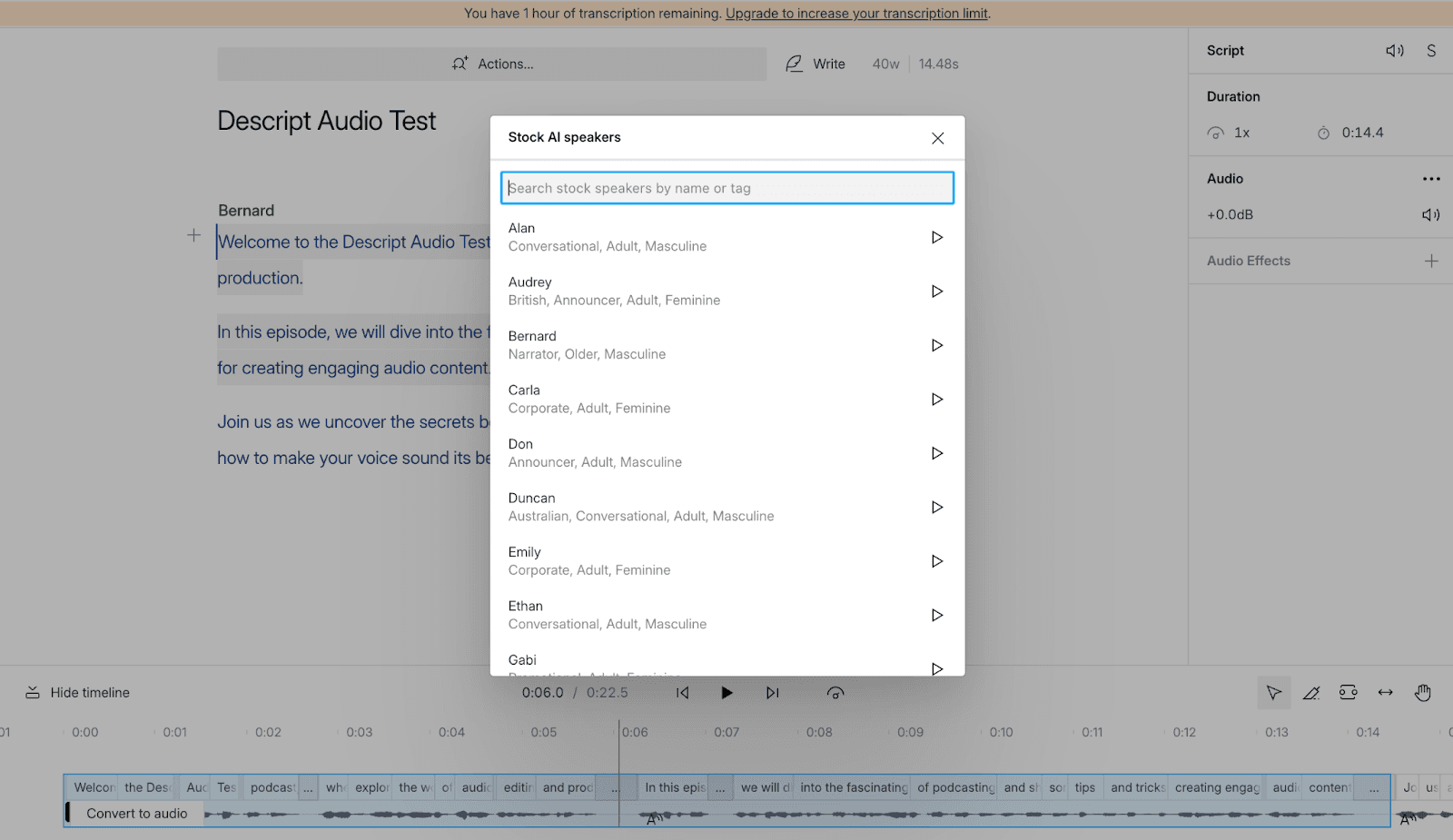
AI 목소리
Kits와 마찬가지로 Descript에는 텍스트 음성 변환에 사용할 수 있는 기본 제공 목소리(stock voices)가 포함되어 있습니다. 목소리의 특징을 설명하는 태그가 달린 총 21개의 목소리가 있습니다: 남성 또는 여성, 젊은 층, 성인 또는 장년층, 그리고 억양과 스타일까지 존재합니다.
Descript에는 Kits의 목소리 학습(Voice Training)과 유사한 목소리 복제(voice cloning) 기능도 있습니다. 흥미롭게도 Descript는 본인의 목소리만 복제할 수 있습니다. 이를 확인하려면 제공되는 특수 대본을 읽는 자신을 템플릿용으로 직접 녹음해야 합니다. 복제된 본인의 목소리는 텍스트 음성 변환뿐만 아니라 향후 자신의 말 위에 덧씌우는 오버더빙(Overdub) 작업용으로 저장해 둘 수 있습니다.
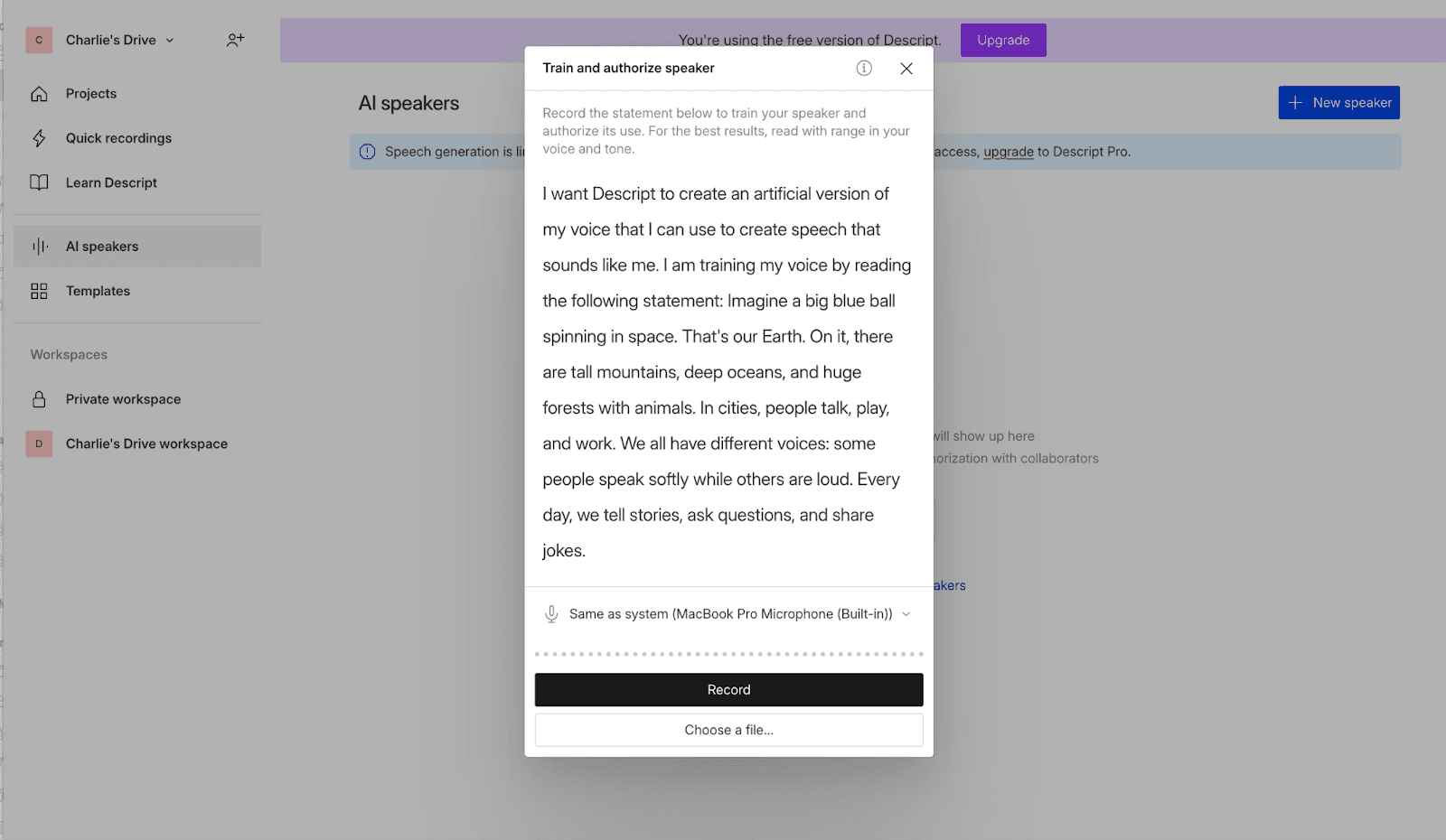
선택 영역 텍스트 재생성 (Regenerate Any Transcription)
재생성(Regenerate)은 기본적으로 (위에서 설명한 긴 과정 없이) 미니 목소리 복제본을 만든 다음, 녹음 대본에서 선택한 텍스트 영역을 다시 생성합니다. 이를 통해 AI 없이는 불가능했을 오디오 편집이 가능해지며, 이는 아마도 Descript의 가장 강력한 기능일 것입니다.
예를 들어, 집에서 녹음하는 중에 초인종이 울렸다고 가정해 보겠습니다. 일반적으로 이 순간을 잘라내는 것은 시간이 많이 걸리는 작업이며, 청취자가 눈치채지 못할 정도로 깔끔하게 처리하는 것은 불가능할 수 있습니다. 하지만 Descript를 사용하면 대본에서 해당 순간을 찾아 하이라이트한 후, 'Replace With(대체)' → 'Regenerate(재생성)'를 클릭하기만 하면 됩니다. 원본 녹음의 해당 섹션 위로 AI가 생성한 말소리가 매끄럽게 채워집니다.
그리고 만약 룸메이트에게 문을 열어달라고 외친 경우는 어떨까요? 대본에서 관련 없는 단어들을 쉽게 삭제할 수 있지만, 청취자가 들을 때 명백히 어색하게 끊기는 현상이 남게 됩니다. 단지 컷 주변의 문구를 Regenerate하기만 하면 AI 목소리가 톤과 억양을 일치시켜 아주 자연스럽게 감춰 줍니다.
오버더빙 (Overdub)
'Replace With(대체)' 메뉴의 Regenerate 아래에는 오버더빙(Overdub) 기능이 있습니다. 편집 작업을 매끄럽게 메우기 위해 AI 목소리를 사용하는 대신, 오버더빙은 팟캐스트에 새로운 단어를 삽입하는 데 사용합니다. 단어를 잘못 발음했거나, 대사를 버벅거렸거나, 단순히 전달력을 살려 제대로 표현하지 못한 경우, 원치 않는 부분을 즉시 잘라내고 AI 오버더빙으로 교체할 수 있습니다.
Descript는 서로 다른 화자를 자동으로 식별하기 때문에 오버더빙이 자동으로 알맞은 화자와 매칭됩니다. 또한, 새 오디오는 주변 녹음의 마이크 음질, 배경 소음 및 억양과 조화를 이룹니다.

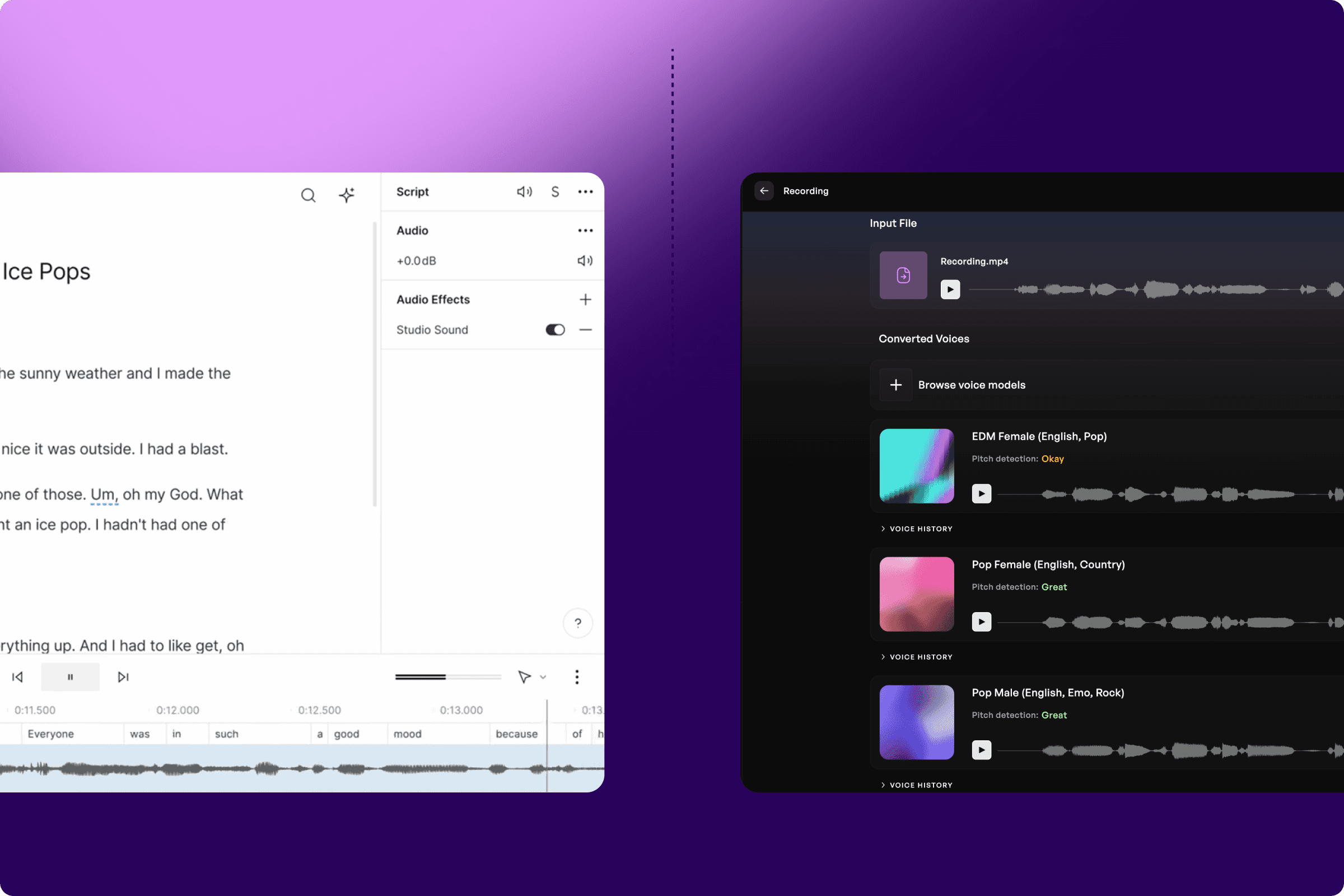
스튜디오 사운드 (Studio Sound)
단 한 번의 클릭만으로 스튜디오 사운드의 알고리즘이 어떤 녹음이든 전문적인 사운드로 탈바꿈시킵니다. 'Audio Effects' 아래의 스위치를 토글하기만 하면, 스튜디오 사운드가 배경 소음으로부터 목소리를 분리하여 양쪽 모두를 향상시켜 줍니다. 'Intensity' 슬라이더를 통해 이 효과를 얼마나 강하게 적용할지 조절할 수 있습니다. 목소리가 보정되기 때문에 스마트폰으로 대충 녹음한 것조차도 고품질 마이크를 사용한 것처럼 선명하게 들립니다. 간단하고 직관적인 단계로 비디오 파일을 완벽하게 다듬고 배경 소음, 쉭쉭거리는 소리(hiss), 방 내의 에코를 제거해 보세요.
필러 워드(추임새) 제거 (Filler Word Removal)
모든 팟캐스터는 이런 경험을 해보았을 것입니다: 에피소드를 녹음할 때는 완벽하게 해냈다고 생각했습니다. 하지만 다시 들어보니 말 속에 "그니까", "어...", "음..." 같은 불필요한 추임새(filler)와 오디오 빈틈이 가득 차 있습니다. 이러한 사소한 것들이 안타깝게도 청취자에게 전달되는 나에 대한 인상에 엄청난 영향을 미칠 수 있습니다.
필러 워드 제거 기능은 Descript에 기본 내장되어 있으며, 다른 기능들과 마찬가지로 사용하기가 믿을 수 없을 정도로 간단합니다. 오디오가 텍스트로 변환되면 추임새 단어 아래에 자동으로 밑줄이 표시됩니다. 별표 아이콘을 클릭한 다음, 편집 도구를 사용해 "Remove filler words(필러 워드 제거)" 및 "Shorten word gaps(말 간격 단축)"를 선택하여 발음을 깔끔하게 정리해 보세요.

나에게 가장 적합한 AI 도구 찾기
Kits와 Descript는 AI 기반 오디오 제작의 최전선에 서 있습니다. 이 두 도구는 기존 워크플로우를 보완하기 위해 매우 쉽고 명료하게 작동합니다. Kits의 목소리 변환 및 목소리 학습, Descript의 텍스트 기반 에디터처럼 강력한 성능과 합리적인 가격 정책을 갖춘 도구들은 이전에는 존재하지 않았던 역동적인 가능성을 열어줍니다. 또한 Kits의 보컬 리무버와 AI 마스터링, Descript의 재생성(Regenerate) 및 필러 워드 제거 기능은 오디오 제작에서 가장 시간이 많이 걸리고 지루한 프로세스들을 없애 줍니다. AI 오디오 도구가 여러분을 어떻게 더 훌륭한 크리에이터로 만들어 줄 수 있을까요?
시작하세요, 무료로.
스튜디오 품질의 AI 오디오 도구로 음성 제작 워크플로를 간소화하세요.
